2. Pandas的Series的创建
pandas的一维的数据结构Series有点像Python的列表list,可以存储一些数据,可以通过index访问Series里某位置上的数据,也可以通过标签label来访问某数据(这点有点类似于Python的字典dict)。 换句话说Series即可像list一样用index来标识Series里某数据,也可像dict那样通过标签来标识某数据。
2.1 创建Series的方法
在创建Series数据结构时首先要引入pandas。然后通过pandas的Series类的构造函数来创建Series对象,即数据。
- 不指定index创建series
import pandas as pd
a = pd.Series([2, 4, 5, 6])
print a
print a[0]
print a[1 : 3]
执行结果如下:
0 2
1 4
2 5
3 6
dtype: int64
2#a[0]
1 4#a[1 : 3]
2 5
dtype: int64
输出的第一列为index,第二列为数据value。这样创建series时没有指定index,pandas会采用整形数据作为该series的index。
从语句print a[1 : 3]可以看出series采用了整形位置信息的index,是可以使用Python里的索引index和切片slice技术。
- 在Series里指定index 用户可以在pandas的Series构造函数里使用index属性,为新建的Series数据指定标识的标签label。
import pandas as pd
s = pd.Series([2, 4, 5, 6], index=list("abcd"))
print s
print "s[b]->", s["b"]
print 's[0 : 3]\n', s[0 : 3]
print 's["a" : "c"]\n', s["a" : "c"]
程序执行结果:
a 2#print s
b 4
c 5
d 6
dtype: int64
s[b]-> 4
s[0 : 3]
a 2
b 4
c 5
dtype: int64
s["a" : "c"]
a 2
b 4
c 5
dtype: int64
- 通过字典构造 在Series构造函数里传入字典数据,即提供了数据又提供了index或者label。
import pandas as pd
s = pd.Series({"a" : 100, "b" : 200, "e" : 300})
print s
结果如下:
a 100# print s
b 200
e 300
dtype: int64
可以看出,字典的key作为Series的index或者label,而字典的value作为Series的value值。
2.2 常用创建Series的方法
上边给出里可以通过list、dict来创建Series等方法,但常用的方法还是list来提供数据和index、label比较好,原因是字典不能有重复的key而列表是允许有重复的。
import pandas as pd
s = pd.Series({"a" : 100, "b" : 200, "e" : 300})
print s
i = ["a", "c", "d", "a"]
v = [2, 4, 5, 7]
t = pd.Series(v, index=i, name = "col_name")
print t
程序执行结果:
a 100# print s
b 200
e 300
dtype: int64
a 2# print t
c 4
d 5
a 7
Name: col_name, dtype: int64
Series构造函数的name参数是给这列数据指定字段名。从结果可以看出t有两个名为'a'的label,值分别为2和7。
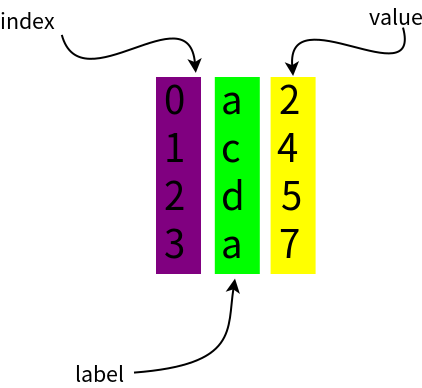
由于Series的label是允许重复的,上边的例子的t里的标签为'a'对应两条数据,但位置信息却不同。
import pandas as pd
s = pd.Series({"a" : 100, "b" : 200, "e" : 300})
print s
i = ["a", "c", "d", "a"]
v = [2, 4, 5, 7]
t = pd.Series(v, index=i, name = "col_name")
print t
print "t['a']\n", t["a"]
print 't[0]', t[0]
print 't[3]', t[3]
执行结果如下:
a 100# print s
b 200
e 300
dtype: int64
a 2# print t
c 4
d 5
a 7
Name: col_name, dtype: int64
t['a']
a 2
a 7
Name: col_name, dtype: int64
t[0] 2
t[3] 7
以上例子在创建Series尽管指定了index参数,实际pandas还是有隐藏的index位置信息的。所以Series有两套描述某条数据的手段:位置和标签。